PythonでChat GPTのAPIを使用してみた。
最近話題になっている ChatGPT。今回は opeai で提供されている API を使用してテスト用の QA ツールを作成して見ようと思うので 解説していこうと思う。まず、API の使い方については openai の公式ページにあるチュートリアルを参考に準備を勧めていこうて思う。 前提として API を使用するには、任意の言語からの HTTP リクエスト、公式の Python バインディング、公式の Node.js ライブラリ、または コミュニティが管理するライブラリをが必要です。また、当然のことですが、openai へのユーザー登録が完了していることも必須です。 今回は公式のPythonバインディングを利用した方法で実施したいと思います。
openai をインストール
まずは、openaiのライブラリーをpipでインストールする。
pip install openai
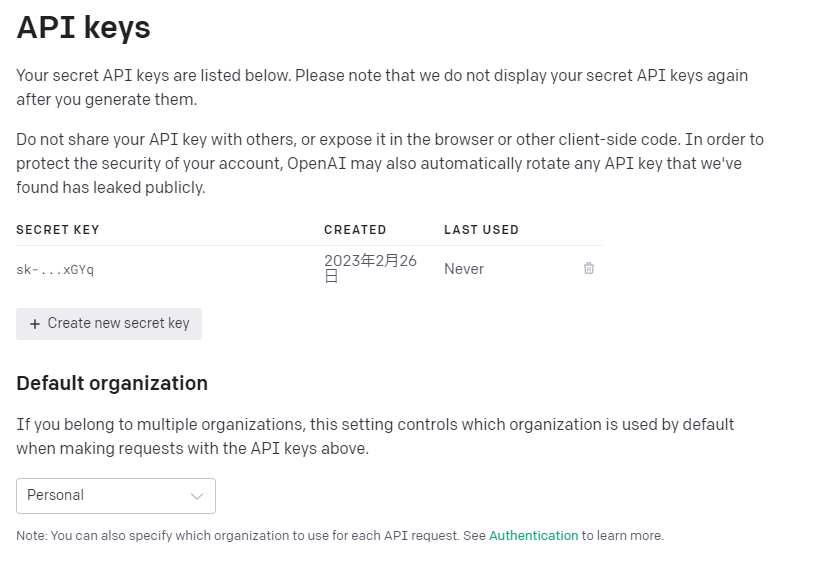
API キーの取得
OpenAI API は、認証に API キーを使用します。API キーのページにアクセスして、リクエストで使用する API キーを取得します。
API キー取得用リンク openai へログインしていることが前提です。
Create new secret key をクリックするとキーが生成されるのでコピーし、環境変数にOPENAI_API_KEYという名前で定義しておこう。 ※環境変数を追加したら PC を再起動すること
要求元組織コード
複数の組織に所属するユーザーの場合は、ヘッダーを渡して、API 要求に使用する組織を指定できます。これらの API 要求からの使用量は、指定された組織のサブスクリプション クォータに対してカウントされます。
組織 ID は、[組織の設定] ページで確認できます。
Python model一覧を取得する。
modelとは様々な機能と価格帯を持つmodelファミリーが存在します。 各モデルによって特徴があるので使い分けることで適切なレスポンスや結果が得られる。 現在提供されいるモデルについては公式リファレンスを参照 openai公式リファレンス
Python では以下のコードでモデルの一覧を取得できる。
import os
import openai
print(os.getenv("OPENAI_API_KEY")) # 環境変数からAPIキーを取得
openai.organization = "org-2WUPn9xRWtpn0BvM13ibQcfK" # 取得した要求元組織コード
openai.api_key = os.getenv("OPENAI_API_KEY") # 取得したAPIキー
r = openai.Model.list() # Moduleの一覧取得
print(str(r))
特定のモデルのみを取得するときは以下
import os
import openai
print(os.getenv("OPENAI_API_KEY")) # 環境変数からAPIキーを取得
openai.organization = "org-2WUPn9xRWtpn0BvM13ibQcfK" # 取得した要求元組織コード
openai.api_key = os.getenv("OPENAI_API_KEY") # 取得したAPIキー
r = openai.Model.list() # Moduleの一覧取得
rr = openai.Model.retrieve(id="text-davinci-003") # 特定のIDのModuleを取得
# print(str(r))
print(str(rr))
ChatGPTへAPIとrequestして結果を出力する。
指定されたプロンプトとパラメーターの入力候補を作成し定義するとChatGPTのAPIからレスポンスがあります。定義できるパラメーターについては、次項で解説します。また、戻り値はJson形式なので、内部で使用するときにはdict型にすると使用しやすい。
import os
import openai
openai.organization = "org-2WUPn9xRWtpn0BvM13ibQcfK" # 取得した要求元組織コード
openai.api_key = os.getenv("OPENAI_API_KEY")
API_Result = openai.Completion.create(
model="text-davinci-003", # 使用するモデルを指定。
prompt="what is hello", # ChatGDPへ送る投稿を設定
max_tokens=7, # 最大トークン数
temperature=0 # 重要度
)
API_Result_dict = API_Result.__dict__ # Dict型へ変換
API_Result_dict_previous = (API_Result_dict['_previous']) #resultのdict分解
API_Result_dict_choices = API_Result_dict_previous['choices'] #resultのdelict分解
for choices in API_Result_dict_choices: # 結果出力
print(choices['text'])
戻り値としてはChatGPTの応答が取得できる。
Hello is a greeting used
パラメーター
model (list) Required
使用するモデルの ID。 List models API を使用して、利用可能なすべてのモデルを表示するか、モデルの概要でそれらの説明を確認できます。
prompt (str or list) Optional Defaults to <|endoftext|>
completionsを生成するプロンプト。文字列、文字列の配列、トークンの配列、またはトークン配列の配列としてエンコードされます。
<|endoftext|> に注意してください
トレーニング中にモデルが認識するドキュメント セパレータ。プロンプトが指定されていない場合、モデルは新しいドキュメントの先頭から生成されます。
suffix (str) Optional Defaults to null
挿入されたテキストの完了の後に来る接尾辞。
max_tokens (int) Optional Defaults to 16
completionsで生成するトークンの最大数。
プロンプト プラスのトークン カウントは、モデルのコンテキスト長を超えることはできません。 ほとんどのモデルのコンテキスト長は 2048 トークンです (4096 をサポートする最新のモデルを除く)。
temperature (int) Optional Defaults to 1
使用するサンプリング温度は 0 から 2 の間です。0.8 のような高い値は出力をよりランダムにしますが、0.2 のような低い値はより集中的で確定的なものにします。
通常、これを変更することをお勧めしますが、両方を変更することはお勧めしません。
top_p (int) Optional Defaults to 1
核サンプリングと呼ばれる、温度によるサンプリングの代替手段であり、モデルは top_p 確率質量を持つトークンの結果を考慮します。 したがって、0.1 は、上位 10% の確率質量を構成するトークンのみが考慮されることを意味します。
通常、これを変更することをお勧めしますが、両方を変更することはお勧めしません。
n (int) Optional Defaults to 1
プロンプトごとに生成するcompletionsの数。
注: このパラメーターは多くのcompletionsを生成するため、トークン クォータをすぐに消費する可能性があります。 慎重に使用し、 および .max_tokensstop の設定が適切であることを確認してください
stream (bool) Optional Defaults to false
部分的な進行状況をストリーム バックするかどうか。 設定されている場合、トークンが使用可能になると、トークンはデータのみのサーバー送信イベントとして送信され、ストリームは message.data: [DONE] で終了します。
logprobs (int) Optional Defaults to null
最も可能性の高いトークンと選択したトークンのログ確率を含めます。 たとえば、is が 5 の場合、API は最も可能性の高い 5 つのトークンのリストを返します。 API は常にサンプリングされたトークンの を返すため、response には最大 までの要素が含まれる場合があります。
の最大値は 5 です。これ以上の値が必要な場合は、ヘルプ センターからご連絡いただき、ユース ケースを説明してください。
echo (bool) Optional Defaults to false
completion に加えてプロンプトをエコーバックする
stop (str or list) Optional Defaults to null
API がそれ以上のトークンの生成を停止する最大 4 つのシーケンス。 返されるテキストには停止シーケンスは含まれません。
presence_penalty (int) Optional Defaults to 0
-2.0 から 2.0 までの数値。 正の値は、それまでのテキストに出現するかどうかに基づいて新しいトークンにペナルティを課し、モデルが新しいトピックについて話す可能性を高めます。
frequency_penalty (int) Optional Defaults to 0
-2.0 から 2.0 までの数値。 正の値は、これまでのテキスト内の既存の頻度に基づいて新しいトークンにペナルティを課し、モデルが同じ行を逐語的に繰り返す可能性を減らします。
best_of (int) Optional Defaults to 1
サーバー側でcompletions を生成し、「最良」 (トークンごとのログ確率が最も高いもの) を返します。 結果はstreamed.best_of できません。
logit_bias (dict) Optional Defaults to null
指定したトークンがcompletionに表示される可能性を変更します。
トークン (GPT トークナイザーのトークン ID で指定) を関連するバイアス値 -100 から 100 にマップする json オブジェクトを受け入れます。このトークナイザー ツール (GPT-2 と GPT-3 の両方で機能します) を使用して テキストからトークン ID へ。 数学的には、バイアスは、サンプリングの前にモデルによって生成されたロジットに追加されます。 正確な効果はモデルごとに異なりますが、-1 から 1 の間の値では、選択の可能性が減少または増加します。 -100 や 100 などの値を指定すると、関連するトークンが禁止または排他的に選択されます。
| 例として、< | endoftext | > トークンが生成されないように渡すことができます。{“50256”: -100} |
user (str) Optional
エンドユーザーを表す一意の識別子。これは、OpenAI が不正行為を監視および検出するのに役立ちます。 もっと詳しく知る。
終わりに
今回は ChatGPT にのAPIについて、解説してみた。 現状のままだと少し実装しにくい点があるので、実際に実装するときにはビジネスロジッククラスを作成して実装していくとその後の開発がスムーズかと感じた。 次回は汎用性のあるクラスコードを書いて共有したいと思う。